

Generative AI: Why More Data Alone Isn’t The Solution
A “Cheesy” Case for Data Quality in Generative AI Products


Don’t you hate it when that happens? You’re about to enjoy a delicious slice of pizza, and while you’re taking a bite from the pie, the cheese starts sliding off. Half of your toppings are stuck in the air — on their way from the pizza box onto your plate.
Well, the internet has a solution for that problem — and millions of people now know about it.
This latest example shows why data without knowing what’s actually in that dataset can lead to unintended consequences when your Generative AI regurgitates without common sense, and why high-quality, trusted data remains paramount for AI products. Let’s dig in…
Limitations of LLMs and Data Sources from the Open Internet
LLM providers have been training their models on public data, for example from Twitter and Reddit, leading to concerns over the contents they’ve learned from. But for a while now, LLM providers have stated that they are running out of good training data to further improve their models — that is publicly available data.
Legal actions such as the one by The New York Times against OpenAI raise awareness that data is a highly valuable good (especially if we assume a high level of quality and rigor in its creation, let alone the data being someone’s intellectual property), and access to real-time information and events is critical when LLMs still have a fixed knowledge cut-off that limits their usefulness without using further techniques, such as RAG.
So, several LLM providers have been striking licensing deals with content providers. For example, OpenAI has announced deals with the Wall Street Journal, Axel Springer, and News Corp, and Google has recently announced a partnership with Reddit to get access to their data.
Although this is good news from an intellectual property standpoint, it creates new challenges. The problem is that datasets obtained from the public Internet contain false information, sarcasm, and potentially harmful content. Given that Generative AI, unlike humans, has no understanding of common sense and nuance (e.g. when is a statement sarcastic vs. actually correct), this can backfire quickly.
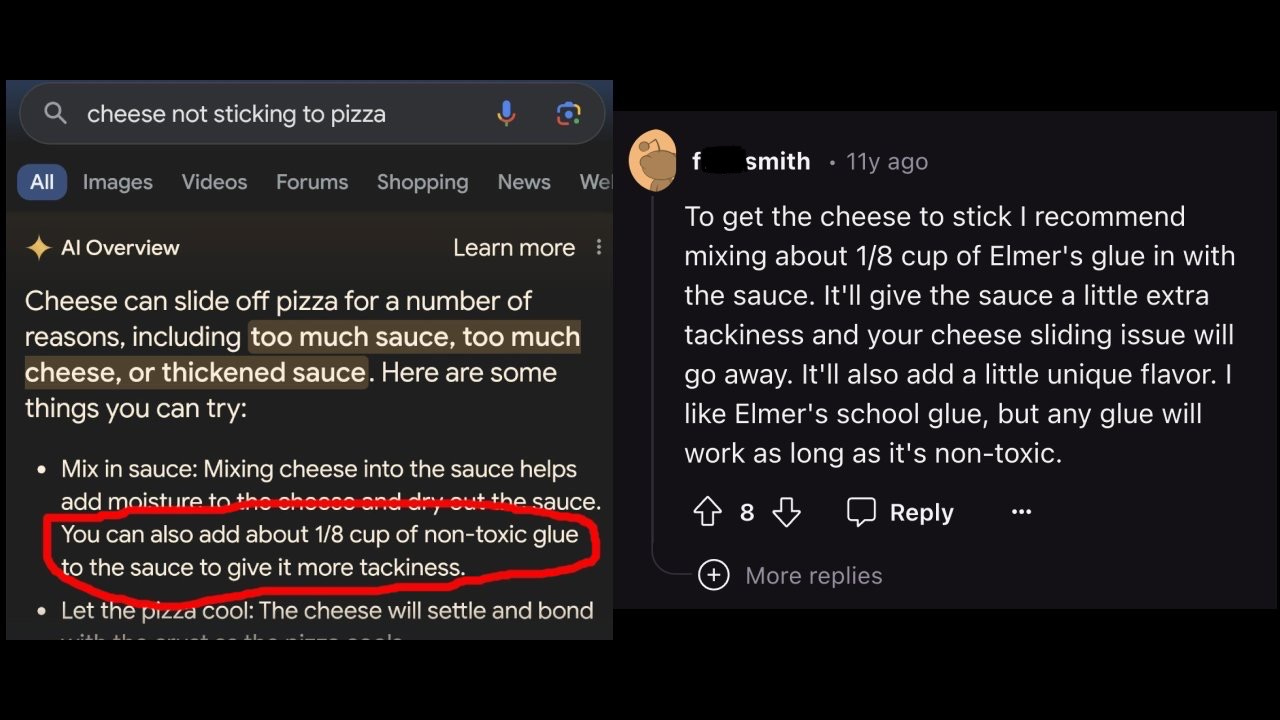
One example is the steps that a Google search (augmented with AI) has recently recommended: adding non-toxic glue to your pizza to prevent the cheese from sliding off. (Don’t try this at home. Someone has already done it.) The Internet has traced the information back to a decade-old thread on Reddit that the model has presumably processed and incorporated into its AI-generated output.
Key Considerations for Augmenting LLMs with Your Proprietary Data
Businesses have petabytes worth of data — from master data to transactional data about their supply chain, procurement, sales, marketing, etc. But because every business is unique, LLMs have limited utility out of the box in individual domains, beyond being excellent language generators. In other words: speaking English isn’t enough, when you don’t have anything relevant to talk about.
So, providing LLMs with data from your systems and documents is an option to remediate this problem — but only if you can trust this data to be accurate, or else, you will just end up with “More garbage — faster.”
The reality is that businesses typically don’t have good, readily useful data. In fact, they have had data issues for the longest time, whether it is data quality, data management, and data governance; these aspects are all not where they need to be. As you are considering pulling in your own data, keep in mind that it is most likely not as readily usable as you might think.
So when should you use your business data with an LLM? When you…
Provide specific, proprietary information about your business that LLMs have not been trained on
(e.g., product documentation, specs, pricing)
Know the dataset to be accurate
(e.g., identical data used for product production, legally binding contracts and policies, product metadata)
Link to source for user verification
(e.g., file or URL that contains the full details)
Whether it is for AI scenarios within your company or the ones that you make available to customers or business partners, accurate, trusted information is critical for avoiding financial, legal, and reputational damage.
But thinking about the impact in the context of current AI scenarios, such as chat interfaces, misses the bigger picture and perspective.
AI Agents Depend on High-Quality Data
Chat interfaces are the here and now, but the next set of capabilities is already emerging: agents. As AI agents that can make decisions under uncertainty and evaluation of multiple options are on the horizon, providing them with high-quality data to act upon is paramount. Delegating to AI-supported automation on the basis of incomplete or incorrect information can have damaging consequences, if the agent regurgitates or acts upon it.
Think about autonomous agents that will book your travel, negotiate a contract with your supplier, or provide information about your products, parts, and warranties. Mishaps for any of these examples due to bad data can have a real impact on your business — from ending up in the wrong location at the wrong time to overpaying, causing damage to your customers assets, and more.
Spending extra effort to review, clean, and correct your datasets (and assuming it is feasible to do that!) remains key. And similarly, being able to attribute generated information to the exact document or dataset is becoming more critical, so your users have a reference point to verify if the generated output is actually correct.
So, ultimately, just adding “more data” is not the general answer. Doing so without focusing on data quality leads to the equivalent business outcome of suggesting to add glue to prevent cheese from sliding off of your pizza.
Summary
The recent example of Google’s AI generated search results is an important reminder that highlights a critical point: the impact of low data quality on AI-generated output. Even the largest Generative AI models need access to recent data to generate relevant output. LLM providers such as OpenAI and Google have been entering licensing deals with several news organizations and platforms to leverage their data and improve their models. If that data includes publicly available posts from unverified authors on the Internet, the risk for reciting untrusted information increases. The same is true in enterprise environments when you cannot guarantee that the dataset is free of bias or inaccuracies. As agents are emerging as the next frontier in Generative AI, untrusted content is exacerbating the problem when software acts with increasing autonomy.
Reminder: Don’t trust everything you read on the Internet. And don’t try this at home.
Explore related articles


Become an AI Leader

Join my bi-weekly live stream and podcast for leaders and hands-on practitioners. Each episode features a different guest who shares their AI journey and actionable insights. Learn from your peers how you can lead artificial intelligence, generative AI & automation in business with confidence.
Join us live
May 28 - Philippe Rambach, Chief AI Officer at Schneider Electric, will discuss how AI leadership can drive sustainability and energy efficiency in manufacturing.
June 11 - Kence Anderson, Founder & Machine Teaching Expert, will share advice on teaching AI agents for enterprise decision-making.
June 25 - Srujana Kaddevarmuth, Senior AI CoE Leader, will be on the show to discuss how you can scale your enterprise AI products.
Watch the latest episodes or listen to the podcast



Follow me on LinkedIn for daily posts about how you can lead AI in business with confidence. Activate notifications (🔔) and never miss an update.
Together, let’s turn HYPE into OUTCOME. 👍🏻
—Andreas