

Large Language Models: Do You Catch My (Prompt) Drift?
Addressing Software Development's New Dependency Triggered By Foundation Model Updates


Something about it felt off. I upgraded to ChatGPT Plus (paid subscription) in March. It was a step up from GPT-3.5. The supposedly more creative, more powerful GPT-4 was now at my fingertips. But the prompt that I had been using over and over again for a few weeks with GPT-3.5 no longer generated results of the same length, tone, and perspective. But even with an updated prompt, GPT-4 has kept generating inconsistent output — especially so between model revisions (e.g. March, May, June). I kept wondering: Was it perception? Bias? Or actually the case?
It triggered a thought: What if these changes in generated output are actually real? What is the impact for software development? Let’s explore it together…

» Watch the latest episodes on YouTube or listen wherever you get your podcasts. «
The Difference Between Generative AI and Traditional Software Development
Software developers have been using APIs to invoke a function or use a remote service that is essential for the application they’re building. Examples of such APIs are authentication, payment processing, or text message notifications. Vendors and providers typically announce in advance which new versions of an API are about to be released as well as which ones are being deprecated. That allows software developers to plan for these changes and incorporate them in a future release or update. And developers can expect that for the duration that they’re using the API in their application, it will perform the same operations defined and documented by the provider, and deliver repeatable results.
When software developers are now integrating generative AI models into their applications, they also rely on APIs. Just like in the previous example, the API through which the model can be instructed to generate an output also has a specification and a documentation. They cover the accepted parameters, their data types, and the format of the output that software developers need to provide or process. In the case of generative AI, developers send a prompt to the model along as one parameter with additional parameters that control the creativity of the generated output, etc.
// OpenAI API reference: https://platform.openai.com/docs/api-reference
{
"model": "gpt-3.5-turbo",
"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"}]
}But there’s an important aspect that is easily overlooked. Generative AI APIs are different — because: You just don’t know exactly what the model will generate and if your prompt generates the same output after a model update.
The Impact Of Model Updates And Prompt Drift
Let’s be clear: probabilistic AI models that are used for predictions, forecasting, etc. also don’t always return the same result. However, the result you receive has a lot less variation in the type and format that is being returned — e.g. a value of 35.7% instead of 42.1% is still floating point number, but the basic premise of how this result is being predicted does not change. The model still generates a numeric prediction.
As time goes on and new data becomes available, the performance of a probabilistic model can degrade. This is especially true when the new data no longer has the same distribution as the data the model had once been trained on (aka model drift). The same concept now also applies to large language models (LLMs) and their model updates. You might also see this being called prompt drift. You will notice it when your prompts are no longer generating the output that you expect, just like I did with ChatGPT. As it turns out, the assumptions I’ve mentioned at the beginning of this post, are independently also part of a new research paper1 that was published last week. The authors examine the very same behavior and find evidence that subsequent model versions of GPT-3.5 and GPT-4 do perform lower on several tasks than their previous versions.
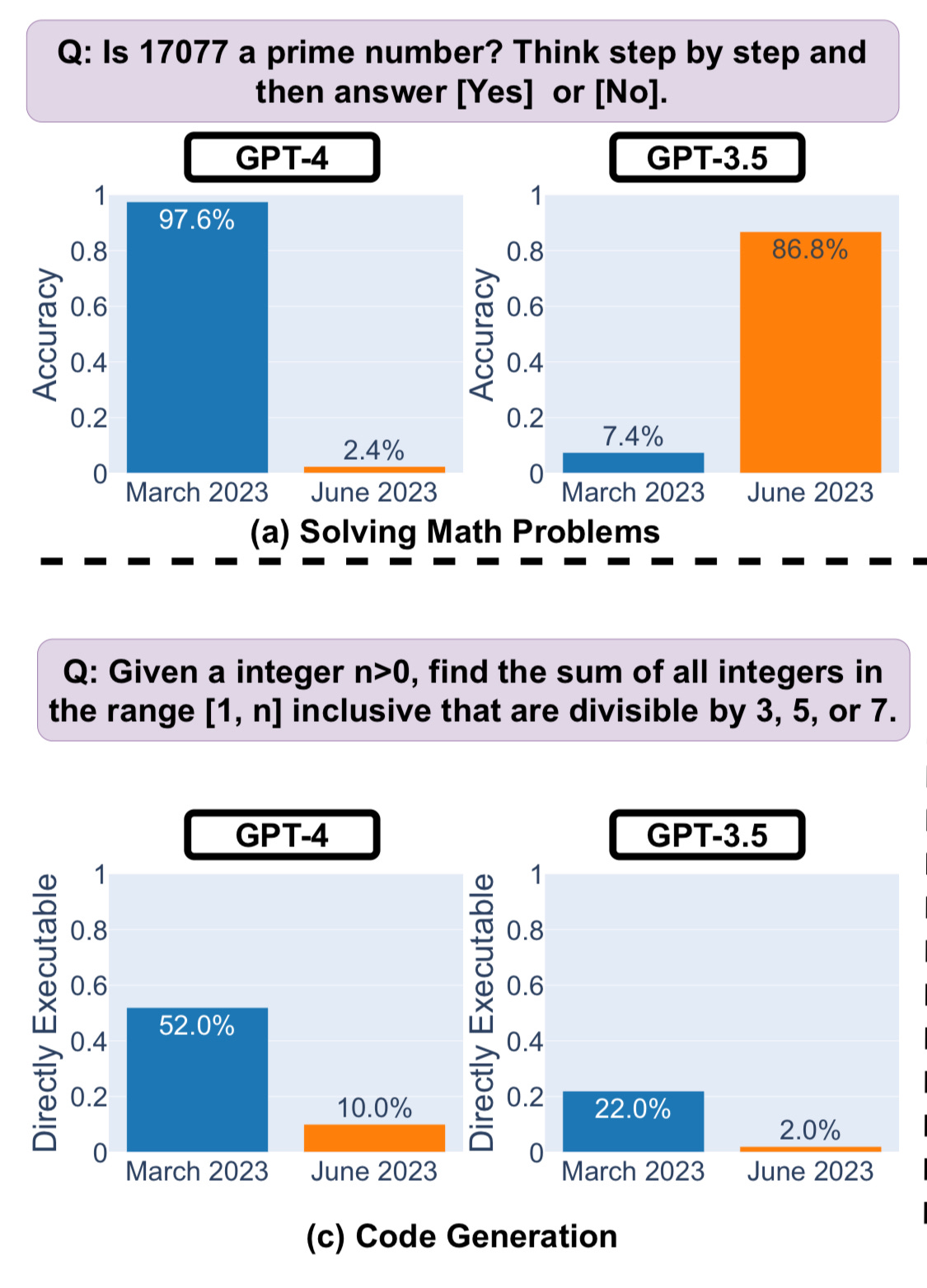
While a variety in the generated output might be desirable for creative tasks (e.g. ad copy, blog posts, or e-mail drafts), business functions like finance or procurement require consistency and factual accuracy. That is why the LLM should generate repeatable, accurate information within the defined boundaries that software developers (and prompt engineers) have defined. Especially when your software is being used by hundreds and thousands of customers and you need to develop, test, and deploy updates and emergency fixes left and right.
The feeds of professional social networks were flooded with statements such as “GPT-4 is getting dumber!”. But that’s only half the story. It misses a key consequence: The operational impact on software development.
What Software Developers Can Do Now
While a variation of output after a model update is already annoying in our lives as consumers, it can create significant risks and costs for professional software developers. Most of all, it creates a new level of uncertainty, whether the product you are developing and that you are responsible for will actually work as expected by your user. And whether it will continue to do so throughout its lifecycle. The former is something that software developers did not have to worry too much about thus far.
Depending upon the industry you serve and the criticality of your software to the business, you will need to take model/ prompt drift into consideration when evaluating generative AI projects to pursue. So what can software developers do right now to literally catch that drift?
Immediate-term (now-3 months):
Periodically check if your provider has updated/ changed the model
Evaluate if the prompts you use in your applications still generate the expected output
If they don’t, adapt & iterate on your prompt, test it, and ship it
Short-term (3-6 months):
Select providers of foundation models based upon your requirements for enterprise-readiness (e.g. heads-up notifications) and their ability to deliver
Incorporate model evaluation frameworks and assessments into your development and operations processes
Mid-term (6-12 months):
Develop programmatic solutions for your applications; for example: store and compare generated output for drift, re-generate & re-evaluate output, and flag2
Consider open-source or commercially available solutions to mitigate this problem
Factor in additional cost and latency for these checks regardless of your implementation
What observations have you made when developing with generative AI?
One thing is certain: evaluating the generated model output (aka “quality assurance”) is becoming a more important task again when using generative AI. Earlier this month, Abi Aryan (Machine Learning Engineer & LLMOps Expert) joined me on “What’s the BUZZ?” and shared her perspective. Catch the full episode: Video | Podcast.
» Watch the latest episodes on YouTube or listen wherever you get your podcasts. «
What’s next?
Join us for the upcoming episodes of “What’s the BUZZ?”
August 1 - Scott Taylor, aka “The Data Whisperer”, will let us in on how effective storytelling help you get AI project funded.
August 17 - Supreet Kaur, AI Product Evangelist, and I will talk about how you can upskill your product teams on generative AI.
August 29 - Eric Fraser, Culture Change Executive, will join and share his first-hand experience how much of his leadership role he is able to automate with generative AI.
Follow me on LinkedIn for daily posts about how you can set up & scale your AI program in the enterprise. Activate notifications (🔔) and never miss an update.
Together, let’s turn hype into outcome. 👍🏻
—Andreas
Chen, Zaharia & Zou (2023), How Is ChatGPT’s Behavior Changing Over Time, Stanford University, Last accessed: 19 July 2023
Potential approach recently suggested by a trusted expert in my network