

Make Your LLM Smarter: A Grounding Experience
Give Your Generative AI Model More Specific Information Beyond Grammar And Syntax


Large Language Models (LLM) that you use “off-the-shelf” create pretty generic output. That’s the going assumption. While it is true for a lot of use cases and it depends on your ability to craft an effective prompt, it’s also similar to the difference between having access to just grammar books and having access to domain-specific textbooks and news on top of that.
If you’ve ever worked in a country where your mother tongue isn’t the dominant language, the following example will be familiar. I’ve had several colleagues and friends share the same point with me over the years. Two colleagues were having a conversation about a work-related topic in English rather than their native language. When I asked one of them, they said: “Yes, I speak French. But I’ve never worked in this domain in France and don’t know the right terminology. But talk about it in English ever day.”
With LLMs, the situation is actually quite similar.
Strengths And Weaknesses Of LLMs
LLMs are extremely good at predicting the next word in a sentence. They have been trained on vast bodies of text from the internet up until a certain point in time. For example, GPT-3.5 and GPT-4 have been trained on data up until January 2022. Any new information after that cut-off date is unknown to these models: scientific breakthroughs, world events, politics, etc. This can limit their usefulness when prompting the model to generate output on a recent topic that it does not have any data on — for example, the new superconductor material ‘reddmatter’1 that was in the headlines this spring (see screenshot).

But despite LLMs missing current information, let’s not forget that they still are a powerful new technology. For example, LLMs can process and store information about an entire book (e.g. Anthropic’s Claude model) and as a user, you can ask questions about the book. LLMs can also translate text into an action or into another language, style, or tone. But the LLM typically doesn’t have deep industry-, domain-, or company-specific context. Hence, its responses can seem rather generic.
On the flip side, though, languages like English haven’t changed dramatically within the last 18 months since the last update of the training data. So, LLMs are highly useful to understand and generate language-based in- and output — just not on the latest news or the deepest domain expertise.
Whether or not generic output is an issue will highly depend on your use case. Respond to an e-mail with the help of an LLM? If it’s about whether and when you’ll meet, for example, a generic reply might just be “good enough”. If it’s about a complex sales deal or a customer support escalation that requires additional details and finesse in handling the relationship, you’d likely want more context and specificity in the reply — and a human to edit it before sending it off.
Approaches For Guiding LLMs
Whether the output an LLM generates is sufficient depends on the use case of which you want to use it. If you need to generate output that is highly domain-specific or based on proprietary data (and training data is not publicly available on the internet), you will likely need to look beyond just prompting the LLM. The same applies to situations in which the LLMs is likely to generate factual inaccuracies and you need to trace the information back to a known source.
Let’s recap the most common approaches to guiding an LLM to generate output:
Prompting: Submit natural language instructions to get the model to create an output. This is the method of choice when you’re looking to generate output that doesn’t need to be highly specific to a domain or be dependent on the latest information.
Examples: Concepts, historic events, known facts
Fine-tuning: Add additional data to the training set and adjusting the model weights. This is a highly resource-intensive process which requires data as well as deep data science expertise.
Example: Finance-specific foundation model
Retrieval-Augmented Generation (RAG): Provide additional content and context to the LLM to draw from when generating an output. This approach promises to be a middle ground for providing the LLM the latest information while being able to trace the answer back to it’s source.
Example: Customer support documentation and purchase history
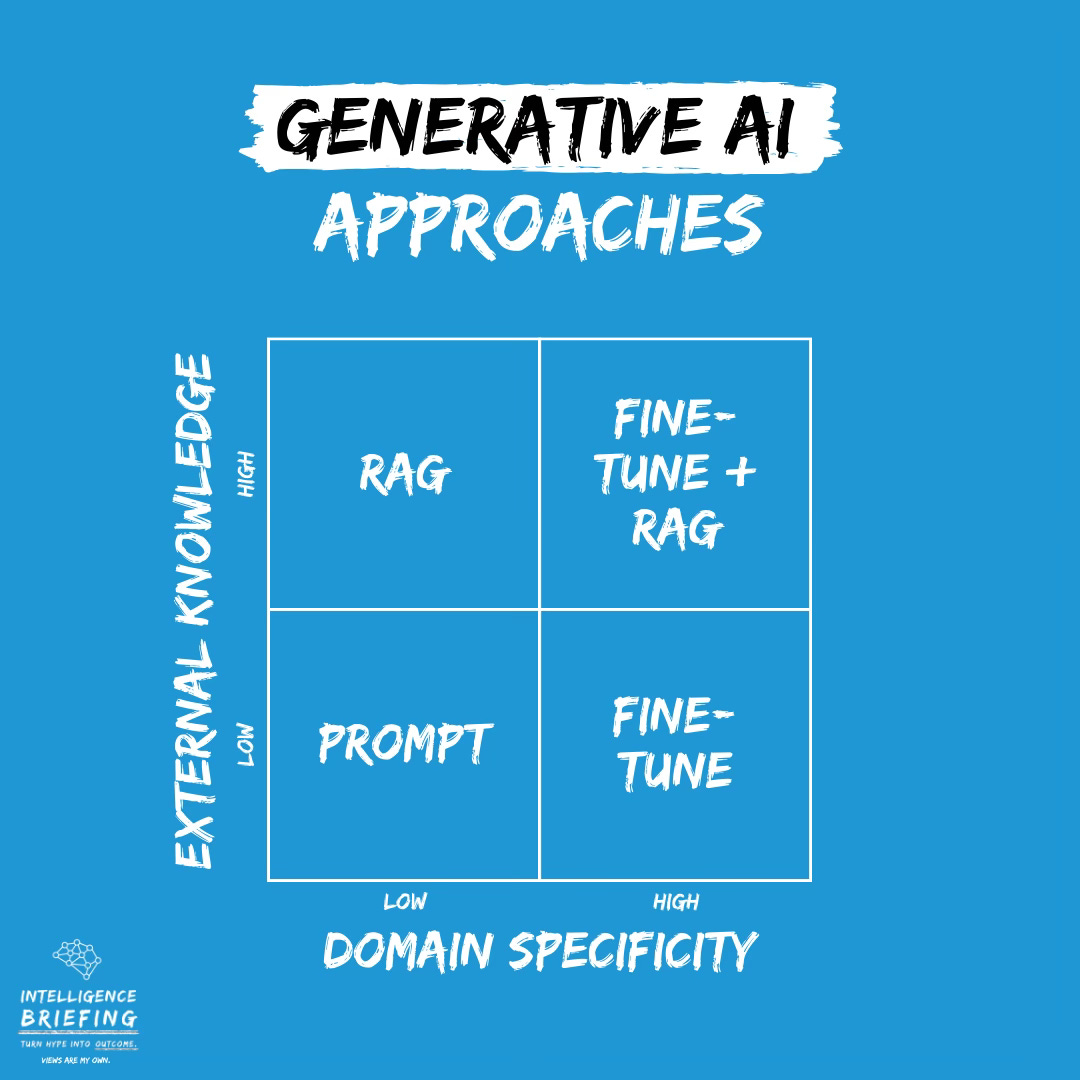
Depending upon the need to use external knowledge and how specific the output should be for a given domain, the following 2x2 provides an overview of the approaches and which to use when. As an example, let’s look at RAG when aiming to balance high demand for external knowledge and low domain specificity.
RAG: Fresh Data For Your LLM
A significant challenge when using LLMs is their tendency to generate factual inaccuracies and making up plausible sounding information that is in fact utter nonsense when they do not have accurate information. To mitigate this behavior, Retrieval-Augmented Generation2, a new approach to providing fresh data to otherwise static, pre-trained LLMs, was first introduced in 2020. It follows the following steps (aka "grounding”):
Preparation
Convert target data (e.g. support documents) into vectors
Store vectors in vector database
Use
Convert user query (prompt) into vectors
Perform semantic search, comparing query vectors (user) with stored vectors (target data)
Augment user prompt with retrieved information
Submit augmented prompt to LLM for output generation

The benefits of this approach are:
Access to current information (→ since model training)
Use of specific information (→ vs generic training data)
Reduction of hallucination (→ more specific context)
Traceability of information (→ known content source)
Prompting is the easiest approach for generating output. However augmenting prompts via RAG provides more contextual and specific information while balancing cost compared to fine-tuning and reducing the risk for hallucinations/ factual inaccuracies.
Now that LLMs can become book smart, what it will it take for them to become street smart?
P.S.: A shout-out to
for providing input on the ideas in this post.Where can you learn more?
Join us live on Tuesday, October 24 at 12:00pm ET | 18:00 CET when , Developer Relations Experts, will join me on “What’s the BUZZ?” and talk about augmenting off-the-shelf LLMs with new data.
Develop your AI leadership skills

Join my bi-weekly live stream and podcast for leaders and hands-on practitioners. Each episode features a different guest who shares their AI journey and actionable insights. Learn from your peers how you can lead artificial intelligence, generative AI & automation in business with confidence.
Join us live
October 12 - Matt Lewis, Chief AI Officer, will discuss how you can grow your role as a Chief AI Officer.
October 24 - Harpreet Sahota, Developer Relations Experts, will join when we talk about augmenting off-the-shelf LLMs with new data.
November 07 - Tobias Zwingmann, AI Advisor & Author, will share which open source technology you need to build your own generative AI application.
Watch the latest episodes or listen to the podcast



Find me here
October 11 - Put Generative AI to Work, Unveiling Tomorrow's Possibilities – Insights from 30 AI Visionaries on the Future of Generative AI in Business.
Follow me on LinkedIn for daily posts about how you can lead AI in business with confidence. Activate notifications (🔔) and never miss an update.
Together, let’s turn HYPE into OUTCOME. 👍🏻
—Andreas
Futurism, Researchers Say They've Created Superconductors At Room Temperature. Created: 08 March 2023. Last accessed: 07 October 2023.
Lewis P. et al., (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://arxiv.org/abs/2005.11401. Last accessed: 04 October 2023.
With the need for RAG in order to get accurate, useful results, wouldn't it be more efficient to just do it yourself? It feels like people are rushing to use AI just because it's there, when it may be be all that great.
"and A significant challenge when using LLMs is their tendency to generate factual inaccuracies and making up plausible sounding information that is in fact utter nonsense when they do not have accurate information. To mitigate this behavior, Retrieval-Augmented Generation2, a new approach to providing fresh data to otherwise static, pre-trained LLMs, was first introduced in 2020."