



Why Good Prompt Engineers Are Worth The Money They’re Making
How Defining The Optimal Prompt Can Make Or Break Your Bank


This spring, TIME reported that Prompt Engineers can make up to $335,000 a year — no college degree required1. Aside from the fact that the ChatGPT hype has led to an abundance of new bootcamps and get-rich-quick schemes being created, computer scientists are wondering: “$335,000 a year? How is that even possible?” Their rationale: prompt engineering is not even an actual engineering discipline.
ChatGPT has taken the world by storm this year. Regardless of your role, domain, or technical background, chances are, you’ve actually engineered a prompt yourself, for example, the last time you’ve instructed ChatGPT, Bing, Bard, or Midjourney to generate an output for you. But, if you think that’s all there is to prompt engineering for generative AI projects, think again. Over the next few weeks, I’ll cover various aspects of prompt engineering in business and why there is merit to learning this skill.
In my last post, I shared why your prompt engineers need more than ChatGPT skills. Today, we’ll look at the impact that effective prompt engineering has on the transactional cost of an application.

» Watch the latest episodes on YouTube or listen wherever you get your podcasts. «
The Variability of Transactional Costs
With generative AI, programming itself is evolving from a set of defined input and output in an artificial language towards designing and submitting instructions in natural language (e.g. “Act as an expert programmer. Create a JSON file for a bowling club application.“). These instructions (prompts) trigger the large language model (LLM) to generate and return an output.
Much like traditional programming when an API is called, there are costs associated with each operation of the LLM as the process to disseminate the prompt and generate an output is resource intensive. In the case of LLMs, this transactional cost varies with the length of each prompt and each generated output. That variability can have a significant impact on your application’s cost as its usage scales. If you estimate too little, you end up eating the cost and it hits your profit margin. If you estimate too much, you might no longer be cost-competitive for your customers.
Effective prompt strategies can mitigate these risks. To better understand the context of estimating the cost, let’s start with how inputs and outputs of LLMs are measured, before we take a deeper look at the transactional cost.
Understanding LLMs’ Ultimate Currency: Tokens
LLMs are trained on vast amounts of text. Each word or sub-part of a word is converted into a so-called token. LLMs then use these tokens to process and generate information: input (prompt) > tokens > processing > generating > tokens > output.
Companies like OpenAI use tokens as the unit of measure to charge their customers — e.g. per 1,000 tokens. In the case of OpenAI’s GPT-3.5 models, roughly 4 characters equal one token or 750 words equal 1-1.5 pages. Let’s look at the prompt that I used to create and he JSON code for the bowling club application in my previous post as a concrete example.
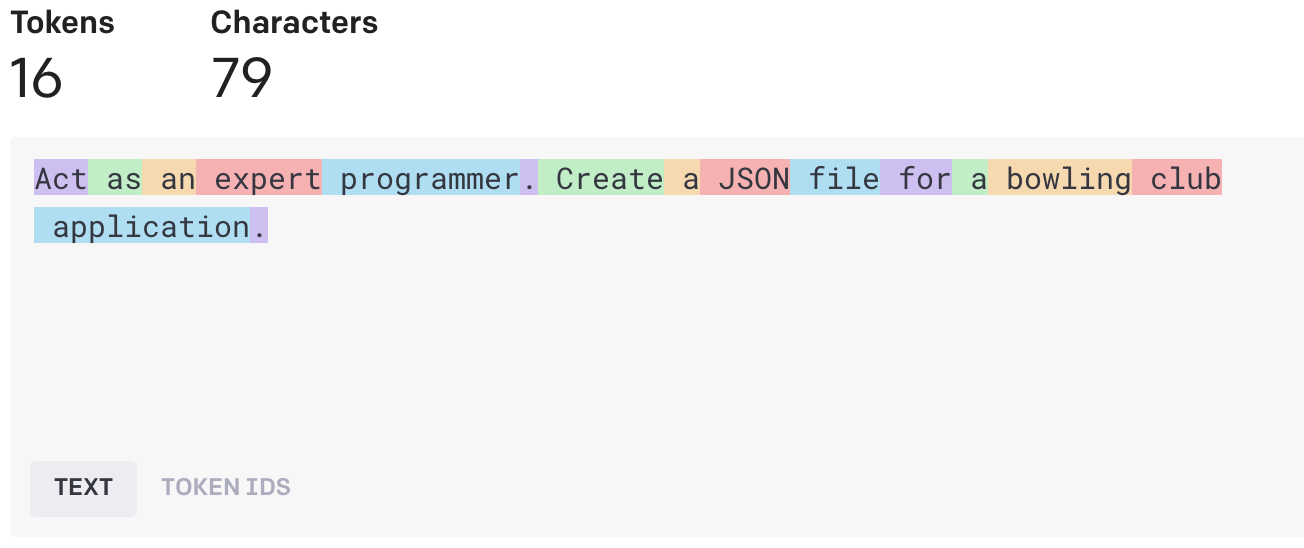
In this example, the color-coding shows the tokens that the model has identified. For example, the word “ programmer“ is one token. This token is equivalent to the number 24292. The more frequent a word is, the lower the number of the token will be.

As you are incorporating generative AI models into your applications, you need to estimate the number of tokens that you expect to process with every transaction — for both, the length of the prompts you submit as well as the length of the output you want to generate. Using publicly available tools, you can estimate the number tokens you will need. For example, OpenAI provides a Tokenizer2 tool to do that.
But how do you determine the transactional cost of incorporating generative AI in your application?
The Optimization Problem Of Prompting
Depending upon the use case, prompt engineers need to optimize for several factors: accuracy of information, low toxicity in the output, repeatability of code, and cost. When using off-the-shelf generative AI models, companies incur costs with every transaction — processing prompts (input) and generating information (output).
For example, OpenAI’s process their GPT-3 models (per 1,000 tokens) as follows:
$0.0004 - Ada
$0.0005 - Babbage
$0.0020 - Curie
$0.0200 - Davinci
The cost of $0.02 for processing 1,000 tokens by itself appears to be negligible, given that it’s single-digit cents. That might be true for a simple transaction, but this transactional cost grows as:
you need longer, more complex prompts (e.g. zero-shot, one-shot with a prompt exceeding 1,000 tokens),
the input data goes beyond short instructions (e.g. when processing entire documents),
the output exceeds a few short lines (e.g. when generating copy for a blog post).
The cost further multiplies with the usage of your generative AI application and how often the generative AI enabled transaction is executed.
Example: Calculating Your LLM Cost
To illustrate the impact, let’s take the example of a complex prompt that includes a set of instructions (e.g. persona and objective) as well as a digitized document (e.g. contract). Using the few-shot approach, the prompt you’ll submit through your application would be 3,000 tokens long (for simplicity’s sake).
[Complex, few-shot prompt] = 3,000 tokens
Price of 1,000 tokens = $0.02 // e.g. OpenAI Davinci model
Price of 3,000 tokens = $0.06 per transaction
Example: 10,000 | 100,000 | 1,000,000 transactions per month
$0.06 * 10,000 = $ 600 per month = $ 7.200 per year
$0.06 * 100,000 = $ 6.000 per month = $ 72.000 per year
$0.06 * 1,000,000 = $ 60.000 per month = $ 720.000 per yearWhat’s the impact if you shortened the prompt to 2,000 tokens, while generating the output with a similar quality?
[Shortened prompt] = 2,000 tokens
Price of 1000 tokens = $0.02 // e.g. OpenAI Davinci model
Price of 2000 tokens = $0.04 per transaction
Example: 10,000 | 100,000 | 1,000,000 transactions per month
$0.04 * 10,000 = $ 400 per month = $ 4.800 per year
$0.04 * 100,000 = $ 4.000 per month = $ 48.000 per year
$0.04 * 1,000,000 = $ 40.000 per month = $ 480.000 per yearIn addition, you need to estimate the cost of the generated output based on the number of tokens that you expect.
Prompt engineers are facing an optimization problem:
Generating the best possible output while using the least amount of input tokens (shortest prompt) and output tokens (shortest generated result).
Are Prompt Engineers Worth Their Money?
As your application’s usage increases, so does the cost of using an LLM. Any additional savings per transaction are multiplied by the number of total transactions. In the above example, with scale, the difference can easily be six figures (example: $240,000 per 1 million monthly transactions). As you change your parameters, such as price per 1,000 tokens or the number of tokens needed (e.g. 2,000 instead of 5,000 tokens), the impact can be even more significant.
To find the optimal combination of prompt length and output quality, prompt engineers need to experiment with different prompts, iterate, and compare the results they can achieve — and decide when they have the optimal result in front of them. Essentially, this is a similar process as you go through yourself when iterating over your ChatGPT or Midjourney prompt until you receive the result you are actually looking for.
Professional prompt engineering therefore requires more than simply defining an instruction for a model to process. It involves developing an understanding of the choice of words, their position in a prompt, experimenting, evaluating outputs, and more. Thats why skilled prompt engineers (or prompt engineering skills) are currently rewarded with a premium in relation to the money their skills can make and save the business. Depending upon the application you’re building, prompt engineers could make their annual salary in the savings they’re able to achieve. But how durable is prompt engineering as a skill or a job profile? I’ll explore that in my next post…
What factors are on your mind when you evaluate generative AI use cases to pursue?
» Watch the latest episodes on YouTube or listen wherever you get your podcasts. «
What’s next?
Join us for the upcoming episodes of “What’s the BUZZ?”
August 1 - Scott Taylor, aka “The Data Whisperer”, will let us in on how effective storytelling help you get AI project funded.
August 17 - Supreet Kaur, AI Product Evangelist, and I will talk about how you can upskill your product teams on generative AI.
August 29 - Eric Fraser, Culture Change Executive, will join and share his first-hand experience how much of his leadership role he is able to with generative AI.
Follow me on LinkedIn for daily posts about how you can set up & scale your AI program in the enterprise. Activate notifications (🔔) and never miss an update.
Together, let’s turn hype into outcome. 👍🏻
—Andreas
How to Get a Six-Figure Job as an AI Prompt Engineer?, TIME, 14 April 2023
GPT Tokenizer, OpenAI, last accessed on 10 July 2023